I have a confession to make. For a while and up until recently, one of my name servers was in fact an open resolver. The way I discovered and fixed the problem was by way of a rather crude DNS based DDOS.
Regular readers (Hi, Bert!) will be aware that I haven't actually published anything noteworthy for a while. So I was a bit surprised to find in early December 2012 that bsdly.net and associated domains was under a DNS based distributed denial of service (DDOS) attack. The attack itself appeared to be nothing special -- just a bunch of machines sending loads and loads of rubbish DNS requests directed at the IP addresses listed as authoritative masters for a few selected domains.
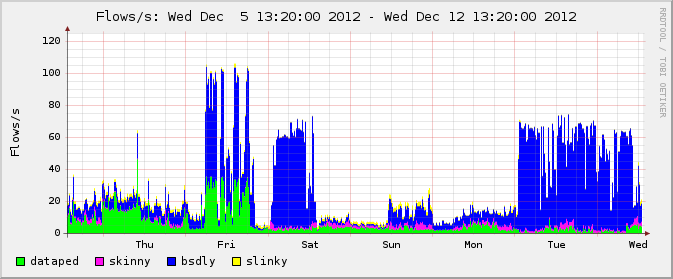
The targets were on relatively modest connections (think SOHO grade), so their pipes were flooded by the traffic and the people who were relying on that connectivity were not getting much network-related done. The sites weren't totally offline, but just about anything would time out without completing and life would be miserable. I've made a graph of the traffic available here, in a weekly view of that approximate period that nicely illustrates normal vs abnormal levels for those networks, generated by nfsen from pflow(4) data.
The networks under attack were in this instance either part of my personal lab or equipment used and relied upon by old friends, so I set out to make things liveable again as soon as I was able. Read on for field notes on practical incident response.
Under Attack? Just Block Them Then!
My early impulse was of course to adjust the PF rules that take care of rapid-fire brute force attacks (see eg the tutorial or the book for info) to swallow up the the rapid-fire DNS as well. That was unfortunately only partially successful. We only achieved small dips in the noise level.
Looking at the traffic via tcpdump(8) and OpenBSD's excellent systat states view revealed that the floods were incoming at a fairly quick pace and was consistently filling up the state table on each of the firewalls, so all timeouts were effectively zero for longish periods. A pfctl -k directed at known attackers would typically show a few thousand states killed, only to see the numbers rise quickly again to the max number of states limit. Even selectively blocking by hand or rate-limiting via pf tricks was only partially effective.
The traffic graphs showed some improvement, but the tcpdump output didn't slow at all. At this point it was getting fairly obvious that the requests were junk -- no sane application will request the same information several thousand times in the space of a few seconds.
It Takes People Skills. Plus whois. And A Back Channel.
So on to the boring part. In most cases what does help, eventually, is contacting the people responsible for the security of the networks where the noise traffic originates. On Unixish systems, you have at your fingertips the whois(1) command, which is designed for that specific purpose. Use it. Feeding a routeable IP adress to whois will in most circumstances turn up useful contact data. In most cases, the address you're looking for is abuse@ or the security officer role for the network or domain.
If you're doing this research while you're the target of a DDOS, you will be thanking yourself for installing a back channel to somewhere that will give you enough connectivity to run whois and send email to the abuse@ addresses. If your job description includes dealing with problems of this type and you don't have that in place already, drop what you're doing and start making arrangements to get a back channel, right now.
Next up, take some time to draft a readable message text you can reuse quickly to convey all relevant information to the persons handling abuse@ mail at the other end.
Be polite (I've found that starting with a "Dear Colleague" helps), to the point, offer relevant information up front and provide links to more (such as in my case tcpdump output) for followup. Stress the urgency of the matter, but do not make threats of any kind, and save the expletives for some other time.
The issue here is to provide enough information to make the other party start working on the problem at their end and preferably inspire them to make that task a high priority one. Do offer an easy point of contact, make sure you can actually read and respond to email at the address you're sending from, and if necessary include the phone number where you are most easily reachable.
When you have a useful template message, get ready to send however many carefully amended copies of that message to however many colleagues (aka abuse@) it takes. Take care to cut and paste correctly, if there's a mismatch between your subject and your message body on anything essential or inconsistencies within your message, more likely than not your message will be discarded as a probable prank. Put any address you think relevant in your Cc: field, but do not hold out any high hopes off useful response from law enforcement. Only directly affected parties will display any interest whatsoever.
Fill in any blanks or template fields with the output from your monitoring tools. But remember, your main assets at this point are your people skills. If the volume is too high or you find the people part difficult, now is the time to enlist somebody to handle communications while you deal with the technical and analysis parts.
You will of course find that there are abuse contact addresses that are in fact black holes (despite the RFC stating basic requirements), and unless you are a name they've heard about you should expect law enforcement to be totally useless. But some useful information may turn up.
Good Tools Help, Beware Of Snake Oil
I've already mentioned monitoring tools, for collecting and analyzing your traffic. There is no question you need to have useful tools in place. What I have ended up doing is to collect NetFlow traffic metadata via OpenBSD's pflow(4) and similar means and monitoring the via NFSen. Other tools exist, and if you're interested in network traffic monitoring in general and NetFlow tools in particular, you could do worse than pick up a copy of Michael W. Lucas' recent book Network Flow Analysis.
Michael chose to work with the flow-tools family of utilities, but he does an outstanding job of explaining the subject in both theory and in the context of practical applications. What you read in Michael's book can easily be transferred to other toolsets once you get at grip on the matter.
Unfortunately, (as you will see from the replies you get to your messages) if you do take an interest in your network traffic and start measuring, you will be one of a very select minority. One rather perverse side effect of 'anti-terror' or 'anti-anythingyouhate' legislation such as the European Union Data Retention Directive and similar log data retention legislation in the works elsewhere is that logging anything not directly associated with the health of your own equipment is likely to become legally burdensome and potentially expensive, so operators will only start logging with a granularity that would be useful in our context once there are clear indications that an incident is underway.
Combine this with the general naive optimism people tend to exhibit (aka 'it won't happen here'), and result is that very few system operators actually have a clue about their network traffic.
Those who do measure their traffic and respond to your queries may turn up useful information - one correspondent was adamant that the outgoing traffic graph for the IP adress I had quoted to them was flat and claimed that what I was likely seeing was my servers being utilized in a DNS amplification attach (very well described by Cloudflare in this blog post). The main takeway here is that since UDP is basically 'fire and forget', unless your application takes special care, it is possible to spoof the source address and target the return traffic at someone else.
My minor quarrel with the theory was that the vast majority of requests were not recursive queries (a rough count based on grep -c on tcpdump output preserved here says that "ANY" queries for domains we did legitimately answer for at the start of the incident outnumbered recursive queries by a ratio better than 10,000 to 1). So DNS amplification may have been a part of the problem, but a rather small one (but do read the Cloudflare article anyway, it contains quite a bit of useful information).
And to make a long story slightly shorter, the most effective means of fighting the attack proved also to be almost alarmingly simple. First off, I moved the authority for the noise generating domains off elsewhere (the domains were essentially dormant anyway, reserved on behalf of a friend of mine some years ago for plans that somehow failed to move forward). That did not have the expected effect: the queries for those domains kept coming beyond the zone files' stated timeouts, aimed at the very same IP adresses as before. The only difference was that those queries were now met with a 'denied' response, as were (after I had found the config error on one host and fixed it) any recursive queries originating from the outside.
The fact that the noisemakers kept coming anyway lead me to a rather obvious conclusion: Any IP address that generates a 'denied' response from our name server is up to no good, and can legitimately be blackhole routed at the Internet-facing interface. Implementing the solution was (no surprise) a matter of cooking up some scriptery, including one that tails the relevant logs closely, greps out the relevant information and one that issues a simple route add -host $offendingip 127.0.0.1 -blackhole for each offending IP address.
My users reported vastly improved network conditions almost immediately, while the number of blackhole routed IP addresses at each site quickly shot up to a 24-hour average somewhere in the low thousands before dropping rather sharply to at first a few hundreds, through a few dozen to, at last count, a total of 5.
There are a number of similar war stories out there, and good number of them end up with a recommendation to buy 'DDOS protection' from some vendor or other (more often than not some proprietary solution where you get no clue about the innards), or to 'provision your stuff to infrastructure that's too big to be DDOSed'. Of these options I would prefer the latter, but this story I think shows that correct use of the tools OpenBSD and other sane operating systems provide for free will go a long way. More kit helps if you're lucky, but smarts win the day.
Should we publish, or 'name and shame'?
I strongly suspect that most of the handful of boxes that are currently blackhole routed by my setup here belong to a specific class of 'security consultant' who for reasons of their own want a piece of the sniffing for recursive resolvers action. But I really can't be certain: I have now way except whois and guesswork to determine who mans the scanning boxes and for what purpose (will they alert owners of any flaws found or save it all for their next attack -- there just is no way to tell). Scans like those (typically involving a query for './A/IN' or the texbook 'isc.org/ANY/IN') are are of course annoying, but whoever operates those boxes are very welcome to contact me in any way they can with data on their legitimate purposes.
During the attack I briefly published a list of the IP addresses that had been active during the last 24 hours to the bsdly.net web site, and for a short while I even included them as a separate section in the bsdly.net blacklist for good measure (an ethically questionable move, since that list is generated for a different and quite specific purpose). I am toying with the idea of publishing the current list of blackholed hosts in some way, possibly dumping to somewhere web-accessible every hour or so, if feedback on this column indicates it would be a useful measure. Please let me know what you think in comments or via email.
For the rest of you out there, please make an effort to keep your systems in trim, well configured with no services running other than for the specific purposes you picked. Keeping your boxes under your own control does take an effort, but it's worth your trouble. Of course there are entire operating environments worth avoiding, and if you're curious about whether any system in your network was somehow involved in the incident, I will answer reasonable requests for specific digging around my data (netflow and other). As a side note, the story I had originally planned to use as an illustration of how useful netflow data is in monitoring and capacity planning involves a case of astoundingly inane use of a Microsoft product in a high dollar density environment, but I'll let that one lie for now.
Good night and good luck.
Update 2019-12-18: Man page links updated to modern-style man.openbsd.org links (no other content change).





{kind=link}
Good post. FYI, flow telemetry is utilized by ISPs all over the world, including Europe, for many purposes, including DDoS detection/classification/traceback. EU privacy/data retention regulations do not preclude the use of flow telemetry.
ReplyDeleteHere are some links to presentations and annual security reports which are focused on DDoS:
https://www.box.com/s/4h2l6f4m8is6jnwk28cg
https://www.box.com/s/llwlaowbthppliyze2uw
Thanks for taking the time to share your experiences!
The -t ANY query is a valid means to generate a reflection attack.
ReplyDeletedig @SKAPET.BSDLY.NET bsdly.net -t ANY
Returns about 500 bytes on a 50 byte query.
The source of the ANY query is nearly always the spoofed target(s) IP address.
One whole internets to you!
ReplyDeleteGreat read and very informative
You'll find this one interesting/similar:
ReplyDeletehttp://www.slideshare.net/mayhemspp/bakeca-ddos-hope
You note correctly that, in the typical DNS-based attack, the source IP address is spoofed (it is a reflection attack). Therefore, what is the point of publishing it? It is the address of the victim, not of the attacker! For the same reason, whois and writing at abuse is quite useless.
ReplyDeleteContacting whoever is listed in whois when there is no way to be sure whether the IP address is spoofed or not is likely to be less useful than otherwise, that's true.
DeleteBut then in a general 'incident response' context, contacting people listed as responsible is more useful, so I left it in, mainly because responses may be useful if only for seeing the problem from a slightly different perspective.
Stéphane is correct and you've not fully comprehended your condition. If you are the target of DNS ANY queries, then you are party TO the larger attack; if you are seeing answers to DNS ANY queries, than you are the target of the attack; in the later case it can be worthwhile to contact source of the unrequested DNS answers; often open resolvers or folks with sizable ANY returns.
ReplyDelete(Stéphane, BTWs, wonderful blog; has come in handy on a few occasions!)